之后会编写一系列集群资源管理的文章,包括:Borg, Mesos, Omega, Yarn。这篇文章先来介绍一下 Borg,写的有问题的地方还请多多指教。
0. 引言
Borg 是 Google 的内部大规模集群管理器,论文于 2015 年发布。目前在云计算领域出尽风头的 Kubernetes 就是 Borg 的开源实现。
在 Google 内部,Borg 负责作业的一系列操作,比如提交、调度、启动、停止等。特性主要包括下面三个部分:
- 用户只需要专注作业开发,需要关注资源管理和失败处理
- 高可用和高可靠性
- 在数以千计的机器上高效运行任务
Borg 之前其实有很多资源管理器了,比如 mesos,yarn,关于这些系统的异同,我们后面的文章里面再细说。
1. Borg Overview
开发者向 Borg 提交 job,每个 job 包含多个 task。多个机器组成一个 cell,每个 job 运行在一个 cell 当中。
1.1 workload
Workload 通俗点理解就是在集群上运行的任务。Borg 上的 workload 主要有两种:
- long-running service:比如在线服务 Gmail。
- batch job:比如一些数据统计工作,类比 Hadoop 系统中的一些批处理作业。
相比 batch job,long-running service 需要保证可用性和低延迟,这也以为着对 borg 要求会更高一点。
在 Google 内部很多应用开发框架构架于 Borg 之上,比如内部 MapReduce 系统,FlumeJava,MillWheel 和 Pregel。这些框架的主要作用是用来开发和提交作业。在这篇文章
1.2 cluster & cell
一个 DC (datacenter) 可以有一个或者多个 cluster,一个 cluster 可以有多个 cell(一个大 cell 和多个小 cell)。这里也意味着 cell 通常不是跨 DC,跨 DC 理论上应该是可行的,只不过会有性能损失。在 Google 内部中等规模的 cell 机器数在 10K 规模,cell 中的机器可以是异构的(异构的意思是机器的一些配置信息,比如 cpu,内存可以不一样)。
1.3 job & task
Borg 的 job 属性包括 job name, owner 和包含的 task 个数。job 可以设置限制 task 的运行限制条件,比如 cpu 架构,os 版本或者 ip 地址。限制条件可以有两种类型:require 和 preference。task 运行的实体是运行一个或者多个进程的容器。
task 也有一些属性:需要的资源和在 job 中的 index。正常同一个 Job 的 task 属性都是一样的,但是可以通过 flags 传参来进行改写。
用户可以通过 Borg 提供的 RPC 调用来查看 job 和一些监控信息。可以通过编写配置(使用 BCL,declarative configuration language,类似 pb 的定义文件 GCL )来定义 job 的元数据。用户可以通过更新配置来更新运行中的 task,某些情况下将导致 task 重跑(比如更新二进制文件),有些情况下不会(比如修改优先级)。task restart 的时候通过捕获信号 SIGTERM 来保存状态信息。
下图是 job 和 task 的状态流转图。
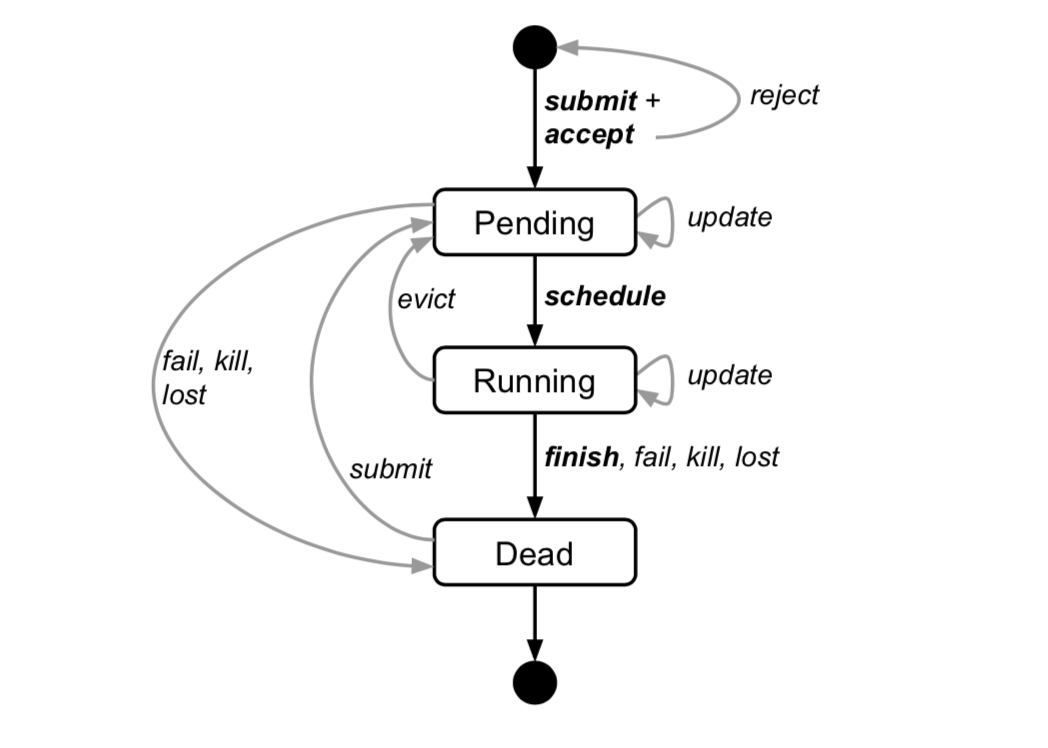
1.4 alloc
alloc 是 allocation 的简称,可以认为是机器的一些资源的封装,多个 task 可以运行在一个 alloc 里面。alloc 里面的资源不管有没有被使用,都将被标记为 assigned。简单理解,alloc 是分配出来的资源,虽然并不会立即使用,但是不能被再次分配了。
alloc set 之于 alloc 类似 job 之于 task。alloc set 里面 alloc 可以分布在不同的机器上。
1.5 Priority, quota, and admission control
在 1.3 里面提了一下 task 的优先级,这里详细说一下。对于多任务的系统,一般都会配置优先级,比如操作系统里面的进程。每个 job 都有一个优先级,正常 job 中的 task 优先级是一样的。Borg 中按用户配置了多套优先级系统,比如 moni- toring, production, batch 的优先级是不重叠的。
具有高优先级的 task 可以抢占低优先级的 task 的资源(killing),这样可能会导致一个瀑布效应:高优先级的 task 把次高优先级的 task 杀掉,次高优先级的 task 重新调度的时候又把更低优先级的 task 杀掉。其实这里有很多种处理方式,比如每次抢占优先级最低,但是论文里面没有写。论文说的只是 production 下的 task 不能进行抢占,因为 production 下的 task 可能是 long-runing 的在线服务。
quota 的中文意思是限额,顾名思义,borg 中的 quota 就是某个优先级资源的限额,在 job 提交的时候先要检查 quota 。通常高优先级的 quota 会占用更多的资源,production 优先级的 quota 是 cell 中可用的资源数。但是低优先级的 quota 是可以大于 cell 中可用的资源数的,也就是可以“超卖”,比如优先级是 0 的 quota 是无限的。如果真的“超卖”往往意外这 task 很长时间里处于 pending 状态。
话说回来,quota 究竟解决了什么问题?如果高效的进行资源调度是很难的问题,使用 quota 机制可以认为是这种问题的一种简单化解决方案。关于资源调度一个很有名的算法叫 Dominant Resource Fairness,简称 DRF,我们后面文章再说。
除此之后,Borg 还提供某些用户一些类似超级管理员的权限,可以对 Borg 中的 Job 进行一些删除等操作。
1.6 Naming and Monitor
在 task 提交到 Borg 之后如何发现就需要寻址服务,Borg 提供的寻址服务是 “Borg name service” (BNS) 。BNS 将运行 task 的 host 的 hostname 写入到一个分布式高可靠的存储中心,Chubby。要寻址一个 task,我们先构造查询的 key,key 由 job,task index,owner,cell 等信息构成,比如用户 ubar 的 jfoo job 的第五十个 task,运行在 cell cc 里面,则构造出来的 key 为 50.jfoo.ubar.cc.borg.google.com。Borg 还将 job 的 size 和 task 的健康信息写入 Chubby 中,这样可以方便做 Load Balance。
运行在 Borg 中每个 task 都运行一个 HTTP server 来提供 task 的监控信息和一些 metrics 信息。一旦 Borg 发现 task 的健康检测请求没有响应,则重启 task。
2. Architecture
Borg 的架构图如下。总的来说是一个 server/agent 架构,主要模块包括 Borgmaster 和 Borglet 等。
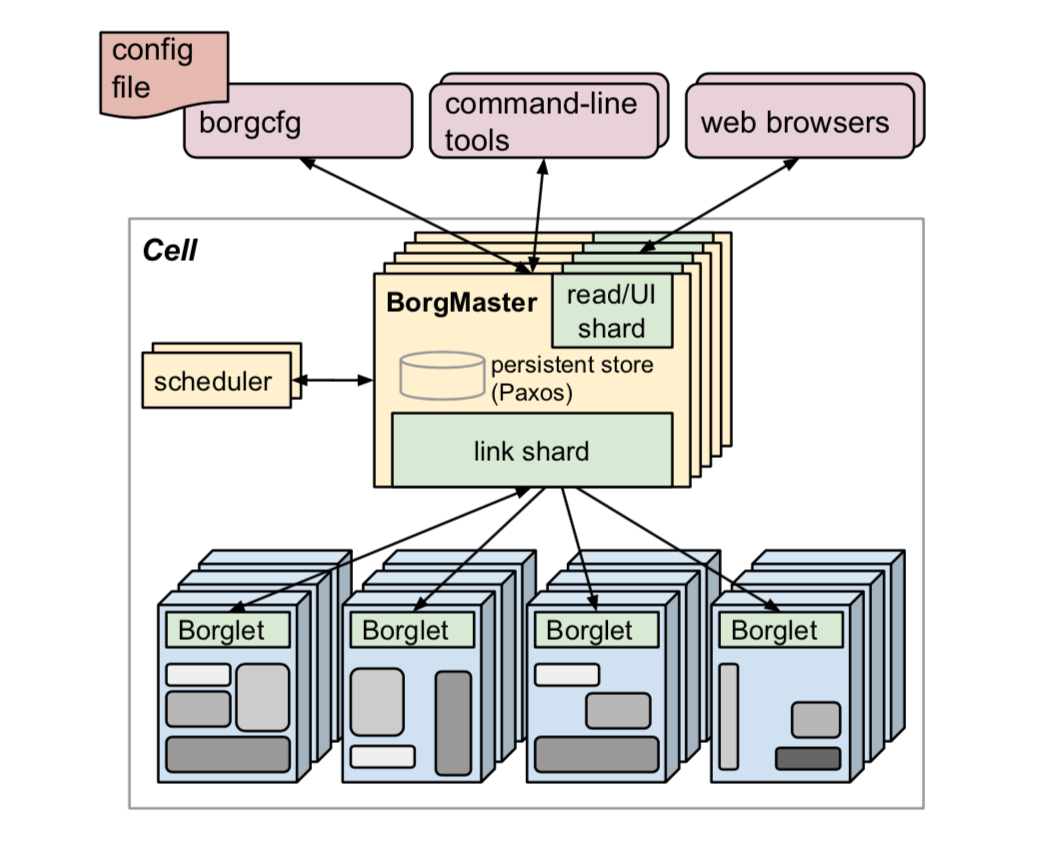
2.1 Borgmaster
Borgmaster 包括两个进程:main Borgmaster 进程和 scheduler 进程。main Borgmaster 进程负责处理 client RPC,比如创建 job 或者信息查询等。除此之后还要维护所有 object (machines, tasks, allocs, etc.) 的状态机。
为了避免单点故障,Borgmaster 一共有五个,通过 Paxos 选出一个 leader 负责所有服务。Borgmaster 的某个时间点状态叫做 checkpoint,会持久化在 Paxos store 里面。通过 checkpoint 我们查看之前所有的 event,以及在某个特定的 checkpoint 上面进行 debug。
2.2 Scheduling
当一个 job 被提交,Borgmaster 会将其记录在 paxos store,然后将 job 的 task 加到 pending 队列。然后 scheduler 会异步地扫描 pending 队列,如果发现有满足条件的机器,就将 task 分配到对应的机器上。扫描过程根据优先级从高到底,主要包括两个步骤:1. feasibility checking(寻找满足运行条件的机器); 2. scoring(从机器里面选择一台)。score 过程主要考虑最小化抢占的 task 个数等因素。
Borg 最开始使用的 score 算法是 E-PVM,后来因为多种原因使用一种混合的式的 score 方法:最小化 stranded resource,因为其他资源被分配完导致无法使用的资源。如果通过 score 选出来的机器没有足够的资源,Borg 将对 task 由优先级从低到高进行抢占(kill),被抢占的 task 将进入 pending 队列。
task 启动时延(从提交到运行)也是一个值得探究的话题,在 Borg 中这个值的中位数为 25s,其中 80% 的时间用于包的安装,安装过程的瓶颈是磁盘写竞争。为了尽量最小化磁盘写竞争的影响,Borg 使用 package 共享的方式:将 task 分配到已经安装了需要的 package 的机器上。除此之外,Borg 使用类似 tree 或者 torrent 的协议来分发包。协议这个地方没有细说,其中 torrrent 协议应该是 P2P,但是 tree 相关的不是很了解。
2.3 Borglet
Borglet 是运行在每台机器上的 agent,主要作用包括:
- task 的启停,以及失败重启。
- 通过 OS kernel 相关设置管理 local resource。
- roll over debug 日志。
- 向 Borgmaster 或者其他的监控系统上报机器的数据。
Borgmaster 和 Borglet 的交互是 Borgmaster 主动请求 Borglet 的方式,这种方式的好处是可以由 Borgmaster 自己做流控,避免 Borgmaster 重启所有 Borglet 流量过来把 Borgmaster 打挂。为了扩展性,每个 Borgmaster 使用一个 link shard 与 Borglet 交互,同时为了保证系统的弹性,Borglet 上报的数据每次都是全量的,然后由 link shard 处理得到增量数据,然后做进一步处理。
如果 Borglet 有多次没有对 Borgmaster 的请求进行响应,Borgmaster 就认为运行 Borglet 的这台机器挂掉了,然后对其上的 task 进行重新调度。
2.4 扩展性
目前一个 cell 的 Borgmaster 可以管理数以千计的机器,有些 cell 大概每分钟运行 10000 个 task。文章表示并不知道扩展性的最终限制会在哪里。下面我们看一下目前为扩展性,Borg 做的一些设计。
早期的 Borgmaster 是一个简单的同步循环来接受请求,调度 task,以及和 Borglet 交互。为了处理大的 cell,scheduler 被独立成一个进程,这样 Borgmaster 的主流程负责其他主要操作,然后再需要 scheduler 的时候和 scheduler 进行交互。可以认为这是一定程度的并行化。
为了提高请求的响应时间,使用多个进程来处理请求。如果对性能还有更高的要求,则将请求分散到 Borgmaster 的 replica 上。正常来说,基于 Paxos 的集群都是由 leader 来处理所有请求,但是对于某些读请求,follower 也是可以处理的。
除此之后还有一些设计使得 scheduler 扩展性更强。
- score cache。对机器进行 score 代价很大,所以可以 cache 下来,在机器状态发生变化的时候进行更新。
- equivalence classes。前面说到一个 job 里面的 task 都是一样的,虽然调度是以 task 进行调度的,但是对一个 Job 中的所有 task 只需要对一个 task 进行 feasibility 和 scoring。
- Relaxed randomization。调度的时候对所有的机器做 feasibility 和 scoring,资源消耗也是巨大的,所以这个过程可以随机选择几台然后找到规定数量的机器即可。
3. 高可用
错误处理是分布式系统中非常重要的一环,Borg 的错误处理主要是通过下面几种技术:
- 增加副本数
- 在分布式文件系统中持久化状态
- 定时保存 checkpoint
举几个具体的例子:
- 自动重新调度被抢占的 task,有时候需要分配到新的机器上
- 减少关联失败
- 在维护升级的时候尽量减少同时失败的 task 个数
- 改变状态的操作使用幂等
- …
对于高可用,Borg 还有一个重要的设计是 Borgmaster 和 Borglet 挂掉的时候,task 还可以运行。当然 Borgmaster 还是要拉起,要不然无法提交 job 了。
通过多种技术 Borg 的可用性可以达到 99.99%。
4. 隔离性
如果保证 task 之间的隔离性是一个绕不过去的话题,包括两方面:security 和 performance。
4.1 security
首先使用 chroot 来对 task 的文件系统进行隔离。其次,为了让用户可以 ssh 进行 debug,最开始采用的方式当用户的 task 运行时则将用户的 sshkey 加入到机器的 authority 中,这样隔离性其实不太好,因为可能会有多个用户的 task 同时运行。后来采用了一种方式 borgssh ,borgssh 和 Borglet 协助创建一个 ssh 隧道到运行特定 task 的 shell 中。
4.2 performance
performance 隔离主要通过将 task 运行在基于 linux cgroup 的容器中,然后在其上增强控制。