距离 Google 的上一篇 F1 论文,也就是 F1: A Distributed SQL Database That Scales 已经 5 年过去了,Google 在今年的 VLDB 上终于发布了 F1 的新版本 F1 Query: Declarative Querying at Scale,我们今天就来看一下这篇论文。安利一下,今天上午在 PingCAP 的 paper party 上,黄东旭大神对这篇论文的讲解非常精彩。
2013 年的 F1 是基于 Spanner,主要提供 OLTP 服务,而新的 F1 则定位则是大一统:旨在处理 OLTP/OLAP/ETL 等多种不同的 workload。但是这篇新的 F1 论文对 OLTP 的讨论则是少之又少,据八卦是 Spanner 开始原生支持之前 F1 的部分功能,导致 F1 对 OLTP 的领地被吞并了。下面看一下论文的具体内容,疏漏之处欢迎指正。
0. 摘要
F1 Query 是一个大一统的 SQL 查询处理平台,可以处理存储在 Google 内部不同存储介质(Bigtable, Spanner, Google Spreadsheet)上面的不同格式文件。简单来说,F1 Query 可以同时支持如下功能:OLTP 查询,低延迟 OLAP 查询,ETL 工作流。F1 Query 的特性包括:
- 为不同数据源的数据提供统一视图
- 利用数据中心的资源提供高吞吐和低延迟的查询
- High Scalability
- Extensibility
1. 背景
在 Google 内部的数据处理和分析的 use case 非常复杂,对很多方面都有不同的要求,比如数据大小、延迟、数据源以及业务逻辑支持。结果导致了许多数据处理系统都只 focus 在一个点上,比如事务式查询、OLAP 查询、ETL 工作流。这些不同的系统往往具有不同的特性,不管是使用还是开发上都会有极大的不便利。
F1 Query 就在这个背景下诞生了,用论文中的话说就是
we present F1 Query, an SQL query engine that is unique not because of its focus on doing one thing well, but instead because it aims to cover all corners of the requirements space for enterprise data processing and analysis.
F1 Query 旨在覆盖数据处理和分析的所有方面。F1 Query 在内部已经应用到了多个产品线,比如 Advertising, Shopping, Analytics 和 Payment。
在 F1 Query 的系统设计过程中,下面几点考量具有非常关键的作用。
- Data Fragmentation: Google 内部的数据由于本身的特性不同,会被存储到不同的存储系统中。这样会导致一个应用程序依赖的数据可能横跨多个数据存储系统中,甚至以不同的文件格式。对于这个问题,F1 Query 对于这些数据提供一个统一的数据视图。
- Datacenter Architecture: F1 Query 的目标是多数据中心,这个和传统的 shared nothing 架构的数据处理系统不同相同。传统的模式为了降低延迟,往往需要考虑 locality,也就是数据和计算越近越好。由于 Google 内部的网络环境优势,locality 的优势显得不是那么重要。所以 F1 Query 更强调计算和存储分离,这样计算节点和存储节点的扩展性(scalability)都会更好。毕竟 Google 内部的系统,scalability 才是第一法则。还有一点值得一提的是,由于使用了 GFS 的更强版本: Colossue File System,磁盘不会成为瓶颈。
- Scalability: 在 F1 Query 中,short query 会在单个节点上执行,larger query 会以分布式的模式执行,largest query 以批处理 MapReduce 模式执行。对于这些模式,F1 Query 可以通过增加运算的并行度来优化。
- Extensibility: 对于那些无法用 SQL 语义来表达的查询需求,F1 通过提供 user-defined functions (UDF)、user-defined aggregate functions (UDAs) 和 table-valued functions (TVF) 来支持。
2. 架构
F1 的架构图如下所示:
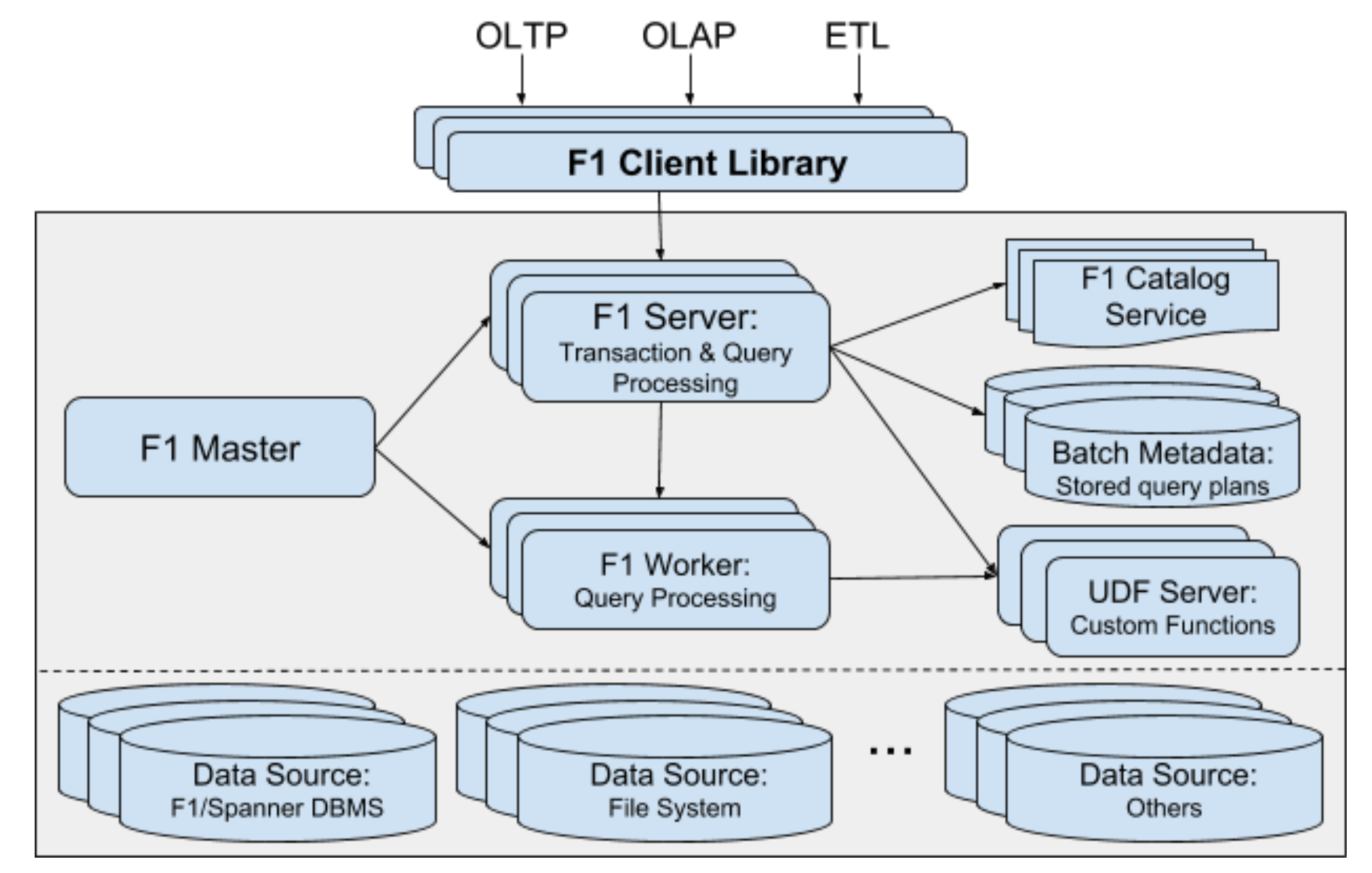
下面的方框里面是每个 Datacenter 一套。关于各个组件的介绍如下:
- 用户通过 client libary 和 F1 Server 交互
- F1 Master 负责 query 的状态的运行时监控和其他组件的管理
- F1 Server 收到用户请求,对于 short query 直接单机执行查询;对于 larger query 转发到多台 worker 上并行执行查询。最后再汇总结果返回给 client。
- F1 Worker 负责具体查询执行
- F1 Server 和 Worker 都是无状态的,方便扩展
2.1 query 执行
用户通过 client libary 提交 query 到 F1 Server 上,F1 Server 首先解析和分析 SQL,然后将涉及到的数据源提取出来,如果某些数据源在当前 datacenter 不存在,则直接将 query 返回给 client 并告知哪些 F1 Server 距离哪些数据源更近。这里直接将请求返回给业务层,由业务层去 retry,设计的也是非常的简单。尽管前面说到要将存储和计算分离,但是这个地方的设计还是考虑到了 locality,datacenter 级别的 locality,毕竟 locality 对查询延迟的影响还是巨大的。
F1 Server 将 query 解析并优化成 DAG,然后由执行层来执行,具体执行模式(interactive 还是 batch)由用户指定。原文是: Based on a client- specified execution mode preference, F1 Query executes queries on F1 servers and workers in an interactive mode or in a batch mode.
对于交互式查询模式(interactive mode)有单节点集中执行模式和多节点分布式执行模式,query 优化会根据启发式的算法来决定采用哪种模式。集中式下,F1 Server 解析分析 query,然后在当前节点上直接执行并接收查询结果。分布式下,接收 query 的 F1 Server 充当一个 query coordinator 的角色,将 query 拆解并下发给 worker。交互式查询在数据量不太大的情况下往往具有不错的性能和高效的资源利用率。
除了交互式查询还有一种模式是批处理模式(batch mode)。批处理模式使用 MapReduce 框架异步提交执行执行,相比交互式这种 long-running 方式,批处理模式的可靠性(reliabitly)更高。
2.2 数据源
数据查询支持跨 datacenter。存储计算分离模式使得多数据源的支持更加简单,比如 Spanner, Bigtable, CSV, columnar file 等。为了支持多数据源,F1 Query 在他们之上抽象出了一层,让数据看起来都是存储在关系型表里面。而各个数据源的元数据就存储在 catalog service 里面。
对于没有存储到 catalog service 里面的表数据,只要提供一个DEFINE TABLE即可查询。
1 | DEFINE TABLE People( |
论文中没有提到的是单看这个 DEFINE TABLE 可以表现力不够,如 @黄东旭 所说这些信息并不足以表现出数据的行为:
- 是否支持 partition?
- 是否支持 逻辑下推?
- 是否支持索引?
- 是否支持多种 扫描模式?
对于新数据源的支持可以通过 Table-Valued Function (TVF) 的方式来支持。
2.3 Data Sink
query 的结果可以直接返回给 client,也可以插入到另外一个表里面。
2.4 SQL
SQL 2011。之所以是 2011 是因为其他老的系统使用的是 2011。
3. 交互式查询
交互式查询模式是默认的查询模式。如前所述,交互式查询有集中式和分布式,具体使用哪种由优化器分析 client 的 query 然后决定。
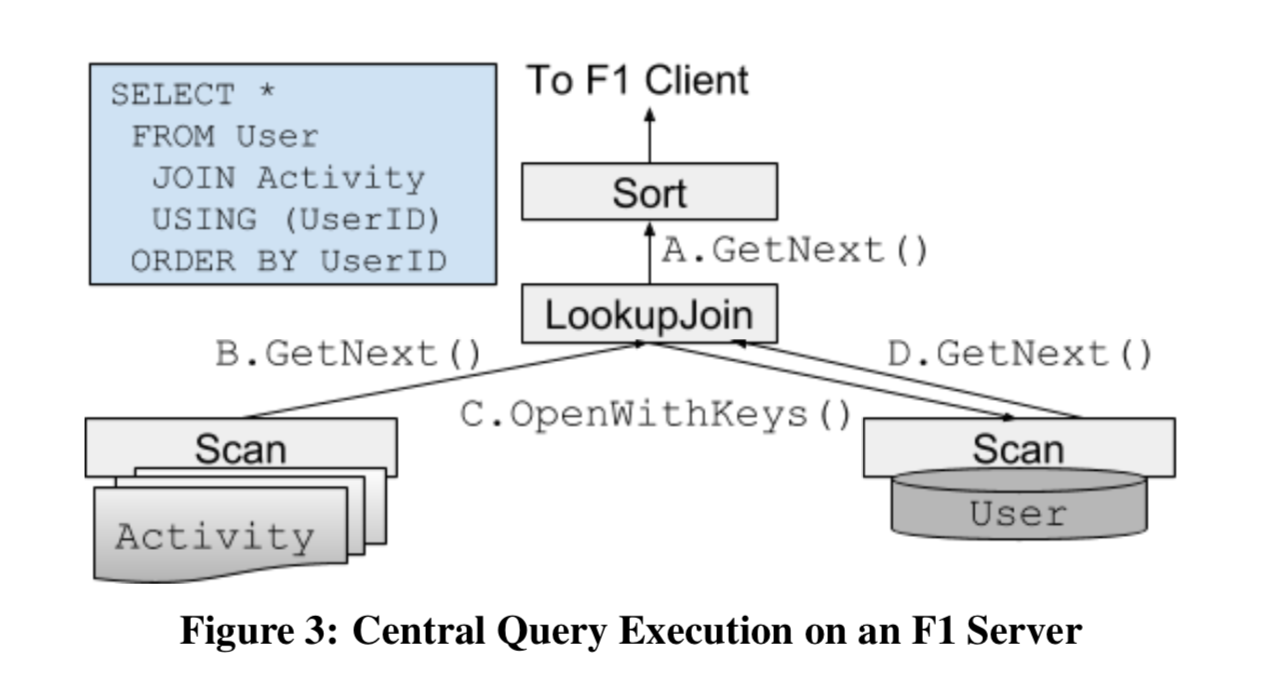
3.1 Single Threaded Execution Kernel
集中式的查询如下图所示,是一种 pull-based 的单线程执行方式。
3.2 Distributed Execution
如前所述,由优化器分析完 query 决定是否采用分布式模式。在分布式这种模式下接收到 query 的 F1 Server 充当一个 coordinator 的角色,将执行 plan 推给 worker。worker 是多线程的,可以并发执行单个 query 的无依赖的 fragment。Fragment 是执行计划切分出来的执行计划片段,非常像 MR 或者 Spark 中的 stage。Fragment 之间通过 Exchange Operator (数据重分布) 连接。
Fragment 的切分过程如下:优化器使用一种基于数据分布依赖的 bottom-up 策略。具体来说每个算子对于输入数据的分布都有要求,比如 hash 或者依赖其他字段的分布。典型的例子有 group by key 和 hash join。如果当前的数据分布满足前后两个算子的要求,则两个算子就被放到一个 Fragment 里面,否则就被分到两个 Fragment 里面,然后通过 Exchange Operator 来连接。
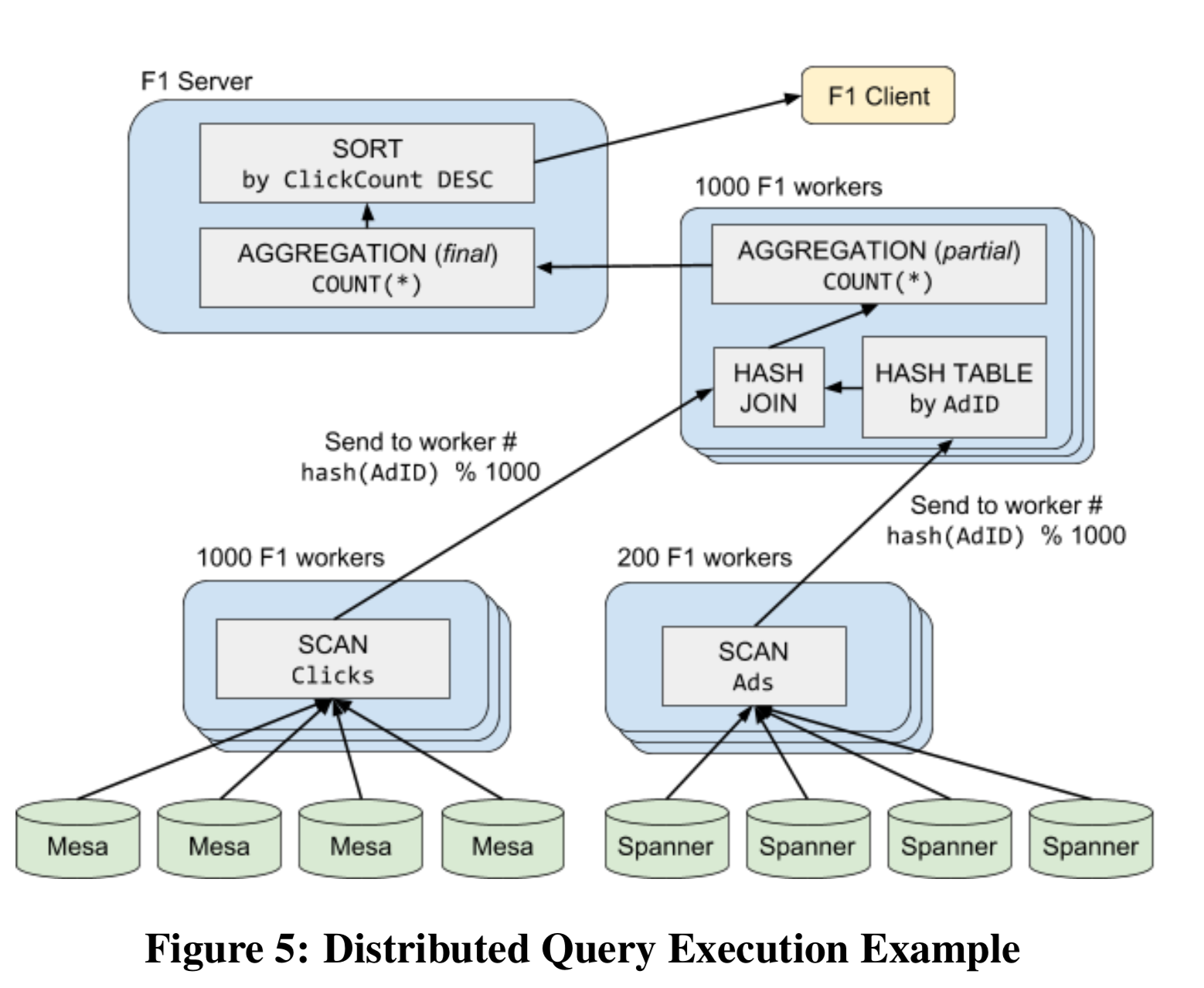
下一步就是计算每个 Fragment 的并行度,Fragment 之间并行度互相独立。叶子节点的 Fragment 的底层 table scan 决定最初的并行度,然后上层通过 width calculator 逐步计算。比如 hash-join 的底层两个 Fragment 分别是 100-worker 和 50-worker,则 hash-join 这个 Fragment 会使用 100-worker 的并行度。下面是一个具体的例子。
1 | SELECT Clicks.Region, COUNT(*) ClickCount |
上面 SQL 对应的 Fragment 和一种可能 worker 并行度如下图所示:
3.3 Partitioning Strategy
数据重分布也就是 Fragment 之间的 Exchange Operator,对于每条数据,数据发送者通过分区函数来计算数据的目的分区数,每个分区数对应一个 worker。Exchange Operator 通过 RPC 调用,扩展可以支持到每个 Fragment 千级的 partion 并发。要求再高就需要使用 batch mode。
查询优化器将 scan 操作作为执行计划的叶子节点和 N 个 worker 节点并发。为了并发执行 scan 操作,数据必须要被并发分布,然后由所有 worker 一起产生输出结果。有时候数据的 partition 会超过 N,而 scan 并发度为 N,多余的 partition 就交由空闲的 worker 去处理,这样可以避免数据倾斜。
3.4 Performance Considerations
F1 Query 的主要性能问题在于数据倾斜和访问模式不佳。Hash join 对于 hot key 尤为敏感。当 hot key 被 worker 载入到内存的时候可能会因为数据量太大而写入磁盘,从而导致性能下降。
论文中举了一个 lookup join 的例子,这里不打算详述了。
对于这种数据倾斜的问题,F1 Query 的解决方案是 Dynamic Key Range,但是论文中对其描述还是不够详细。
F1 Query 对于交互式查询采用存内存计算,而且没有 check point。因为是内存计算,所以速度非常的快,但是由于没有 checkpoint 等 failover 的机制,只能依赖于业务层的重试。
4. 批处理
像 ETL,都是通过 Batch Mode 来处理的。Google 以前都是通过 MapReduce 或者 FlumeJava 来开发的,开发成本一般比较高。相比 SQL 这种方式,不能有效复用 SQL 优化,所以 F1 Query 选择使用 SQL 来做。
如前所述,交互式查询不适合处理 worker failure,而 batch mode,也就是批处理这种模式特别适合处理 failover(每一个 stage 结果落盘)。批处理模式复用交互式 SQL query 的一些特性,比如 query 优化,执行计划生成。交互式模式和批处理模式的核心区别在于调度方式不同:交互式模式是同步的,而批处理模式是异步的。
4.1 Batch Execution Framework
批处理使用的框架是 MapReduce,Fragment 被抽象成 MapReduce 中的 stage,stage 的输出结果被存储到 Colossus file system (GFS 二代)。
在 Fragment 映射有一点值得注意的是严格来说,Fragment 的 DAG 映射到 mr 是 map-reduce-reduce,对这种模式做一个简单的变通变成:map-reduce-map<identity>-reduce,如下图:
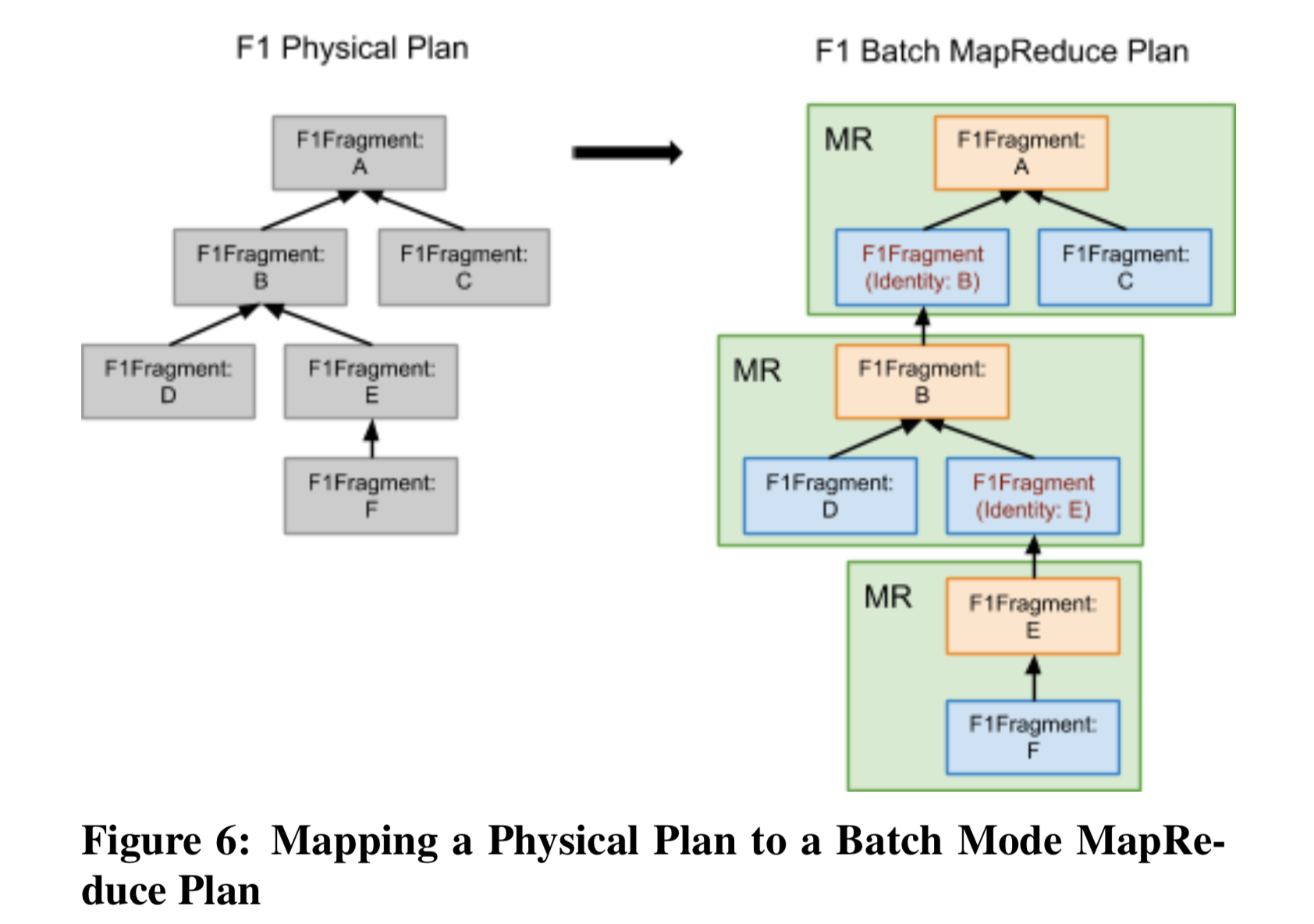
关于 MapReduce 的更详细信息可以参考 Google 03 年那篇论文。
4.2 Batch Service Framework
Framework 会对 batch mode query 的执行进行编排。具体包括:query 注册,query 分发,调度已经监控 mr 作业的执行。当 F1 Server 接收到一个 batch mode query,它会先生成执行计划并将 query 注册到 Query Registry,全局唯一的 Spanner db,用来 track batch mode query。Query Distributor 然后将 query 分发给 datacenter。Query Scheduler 会定期从 Registry 拿到 query,然后生成执行计划并交给 Query Executor 来处理。
Service Framework 的健壮性非常好:Query Distributor 是选主(master-elect)模式;Query Scheduler 在每个 datacenter 有多个。query 的所有执行状态都是保存在 Query Registry,这就保证其他的组件是无状态的。容错处理:MapReduce 的 stage 会被重试,如果 datacenter 出问题,query 会被分配到新的 datacenter 上重新执行。
5. 优化器
SQL 优化器类似 Spark Catalyst,架构如下图,不细说了。
6. EXTENSIBILITY
对于很多复杂业务逻辑无法用 SQL 来描述,F1 针对这种情况提供了一种用户自定义函数的方法,包括 UDF (user-define functions),UDA (aggrega- tion functions) 和 TVF (table-valued functions)。自定义函数开发语言支持 SQL、LUA、SQL 和其它高级语言,实现在 UDF Server 上。
UDF Server 和 F1 Query 是 RPC 调用关系,有 client 单独部署在同一个 datacenter。udf server 完全有 client 来控制,无状态,基本可以无限扩展。
6.1 Scalar Functions
UDF 并不是新的概念,UDF Server 这种部署方式看上去还算新颖一点。但是 UDF Server 这种单独部署模式一个可能的问题是延迟问题,这里通过批量流水线的方式来减少延迟。下面是 UDF 的一个例子。
1 | local function string2unixtime(value) |
6.2 Aggregate Functions
UDA 是对多行输入产生一个单一的输出,要实现 UDA,用户需要实现算子 Initialize, Accumulate, and Finalize。另外如要要对多个 UDA 的子聚合结果进行再聚合,用户可以实现 Reaccumulate。
6.4 Table-Valued Functions
TVF 的输入是一个 table,输出是另外一个 table。这种在机器学习的模型训练场景下比较有用。下面是论文中的具体的一个例子:EventsFromPastDays 就是一个 TVF。
1 | SELECT * FROM EventsFromPastDays( |
当然 TVF 也支持用 SQL 来描述,如下。
1 | CREATE TABLE FUNCTION EventsFromPastDays( |
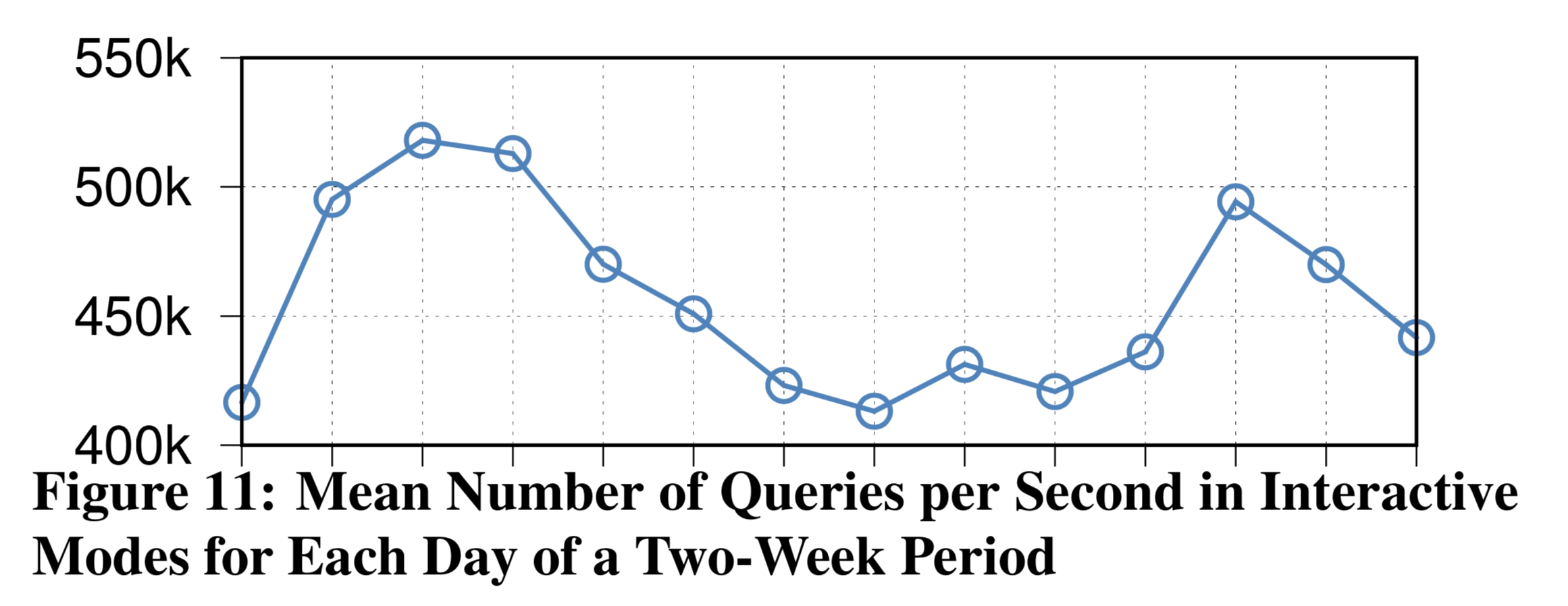
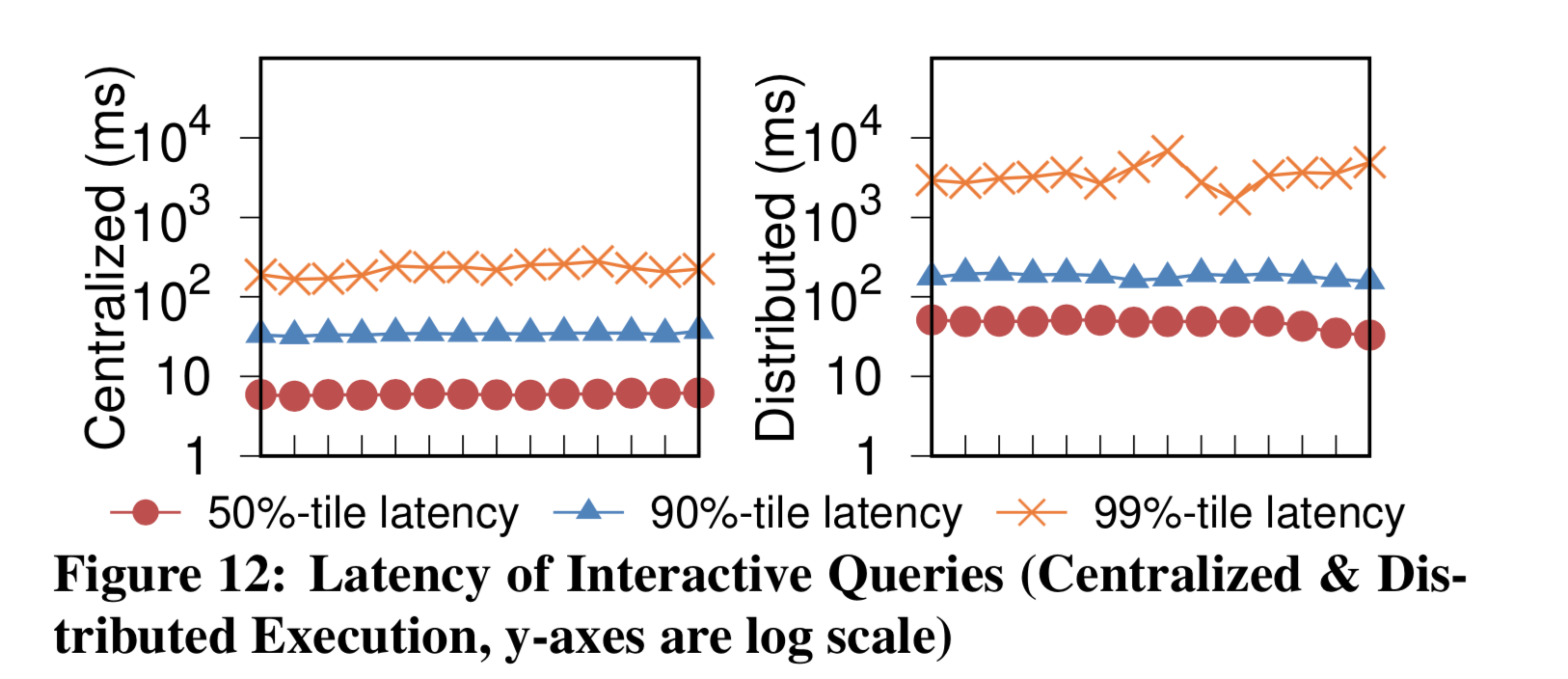
7. Production Metric
下面是 F1 Query 在 Production 环境下的几个 metrics。
8. 总结
回过头来看 F1 Query 最新的这篇论文给人最大的启发就是大一统的思想,这个应该也是行业发展趋势。回想一下 MapReduce 论文由 Google 于 2003 年发表,开源实现 Hadoop 于 2005 问世。不妨期待了一下未来的 3 到 5 年的 F1 Query 的开源产品。
最后再感谢一下 PingCAP 以及 @黄东旭。meetup 分享很赞。